序
在知乎上看到两篇 吹嘘 云风的 coroutine 库的文章。
人啊就是这样的,出名了以后,就是垃圾也有人吹捧。
今天来点评下,云风的 coroutine 到底垃圾在哪里。又或者说,一个优秀的协程,应该优秀在哪里。
云风错在哪里
首先一个优秀的协程库,要做到“自然”。
什么是“自然”呢?就是要做到尽量不改变原来写同步阻塞IO逻辑的时候的代码。
因此引出第一错:
1 协程库不应该侵入 API 设计
要使用云风的协程,被调度的协程必须有如下的函数签名
void coroutine_function(struct schedule *S, void* arg);
注意到那个 struct schedule *S 参数了吗?要使用协程,必须带上这个参数。
哪怕本层级的函数并不直接调用 IO, 也就是不会直接用到 struct schedule *S 参数,他也得带上,并将 struct schedule *S 传给所有他要调用的函数。
也就是整个程序所有的函数都得带上 struct schedule *S 参数。
这也是 asio 的有栈协程设计失败的地方。一旦使用了有栈协程,所有的函数都得加上
asio::yield_context参数。
如果只是某个会调用 IO 的函数需要带上这个 休眠器 还好。但是假设这样的调用链条
A -> B -> C -> D, 最终在 D函数里调用了 async_read();
那显然,为了让整条路径能实现逐级传递 struct schedule *S, 必然会让这条调用链上的所有函数都带上 struct schedule *S 参数。
但是,如果是 语言自己就支持协程,那么整个层级都得带
async标记,似乎也是传染? 并不是的。因为async是语言的一部分。使用了async并不会导致你整条调用链都捆绑到某个协程库上。因此语言内置的协程,是可以传染,并且不能算是一个坏设计。
2 协程库不应该强依赖一个调度器
c++20 协程设计,和以往的协程设计有一个显著的不同点:它不依赖某个调度器去调度协程。
这点,上看,不能说云风的错。应该是因为时代的局限性。云风写此库的年代,协程是必须要依赖一个调度器去调度的。毕竟那时候的理论,就是说 协程是用户调度的线程。
但是,时代的局限性也是局限性。不能因为是时代造就的缺点就不准批判。正如站在21世纪的我们,不能倒回去去夸奖封建王朝,并且对封建时代的弊病以“时代局限性”为由视而不见。
今人并不比古人更聪明,但是今人一定比古人有更多的见识。古人的错误必须要认识,吸取,并避免。
那么,为何 协程库不应该依赖调度器呢?
先来看下不依赖调度器的协程库该有的 api 和 使用方式
ucoro::awaitable<int> coro_compute_int(int value)
{
co_return (value * 100);
}
ucoro::awaitable<void> coro_compute_exec(int value)
{
auto x = co_await ucoro::local_storage;
std::cout << "local storage: " << std::any_cast<std::string>(x) << std::endl;
auto comput_promise = coro_compute_int(value);
auto ret = co_await std::move(comput_promise);
std::cout << "return: " << ret << std::endl;
}
ucoro::awaitable<void> coro_compute()
{
for (auto i = 0; i < 100; i+=2)
{
co_await coro_compute_exec(i);
co_await coro_compute_exec(i+1).detach(std::string{"hello from detached coro"});
}
}
int main(int argc, char **argv)
{
std::string str = "hello from main coro";
coro_compute().detach(str);
return 0;
}
表面上看,用了 co_await,用了协程,但是你会发现,实际上 main() 里并没有调用 协程的调度器。
整个协程还是自然的运转起来了。
有人会问,那不依赖调度器的协程,要怎么实现异步IO呢?
那看下面这个稍加修改的例子
ucoro::awaitable<int> coro_compute_int(int value)
{
auto ret = co_await callback_awaitable<int>([value](auto handle) {
std::cout << value << " value\n";
handle(value * 100);
});
co_return (value + ret);
}
ucoro::awaitable<void> coro_compute_exec(int value)
{
auto comput_promise = coro_compute_int(value);
auto ret = co_await std::move(comput_promise);
std::cout << "return: " << ret << std::endl;
co_return;
}
ucoro::awaitable<void> coro_compute()
{
for (auto i = 0; i < 100; i++)
{
co_await coro_compute_exec(i);
}
}
int main(int argc, char **argv)
{
coro_compute().detach();
return 0;
}
在 coro_compute_int 里,最终通过
auto ret = co_await callback_awaitable<int>([value](auto handle) {
std::cout << value << " value\n";
handle(value * 100);
});
这个代码,实现将协程转成了一个回调函数。
如果这里调用了一个 发起IO/完成回调 这种性质的proactor类型的网络库。 那么这个协程就实现了在那一刻,整个调用链被挂起。
然后等待 网络库的调度。
没错,协程自身并不提供一个调度器。而是可选的依赖用户代码现有的“完成回调”机制来实现协程调度。
看起来,如果是云风的库,好像最后写一个 lambda ,然后将 lambda 作为 完成回调。并在完成回调里调用 coroutine_resume 似乎也能实现啊?
那么为什么我还是说云风这个库设计是错误的呢?
因为他这个库,脱离了调度器并不能运转。也就是说,如果没有一个调度器去运行 coroutine_resume, 则整个协程就无法运转起来了。具体下个章节会讲为何。
但是,他的设计,还是有一定的优秀之处的,就是他的协程,可以和其他的调度器搭配使用。 这个和那种内置调度器的 协程库,有着天壤之别。没错,我就是在批评 腾讯的 libco 。libco至少在设计上远不如云风的库。
如果说云风的库,是错在需要一个调度器,而 libco 错的更离谱, 直接强行内置一个调度器。要把它的协程直接当线程看待。是的,由此可以认定 libgo 也是错误设计,还有 gochannel 更是错误的离谱。
3. 云风的协程库栈设计是错误的
前面2点,是基于接口设计的理念进行批评的,接下来,就是直面其 C 语言功底的时候了。 前面两个设计缺陷,可以用时代的局限性搪塞。接下来的错误,就不应该犯了,至少不应该是一个为网易编写过游戏引擎的人应该犯的错误。
接下来的点评,会摘录一部分 云风的代码 来配合讲解
看一个协程库,一般看3个地方:协程 创建,协程 死亡,协程切换。
我们首先看协程的切换。
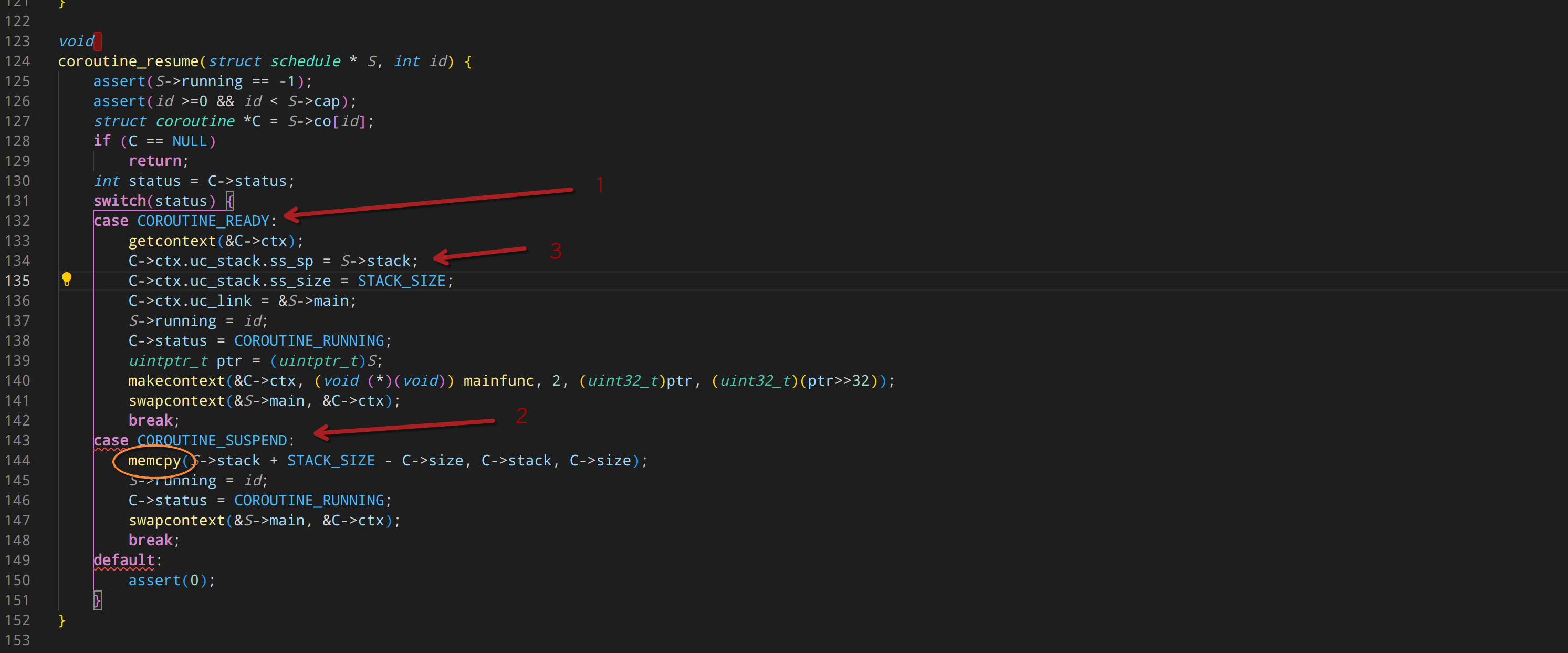
前面有人可能不服气,以为我说云风的库强行依赖调度器是我黑他。现在看了这个代码的 1 号位置应该是服气了吧。 因为云风的协程,在 创建的时候,仅仅是做了个标记。 真正的创建,是在 切换调度的代码里。在 1 号位这个地方。
不跑个调度器,根本连运行都运行不起来。
我们看下2号位的代码,会发现里面赫然一个 memcpy。
这是什么鬼??
原来云风的协程啊,是通过 memcpy 实现“栈切换”的。
这种惊为天人的操作,实在是,我看不懂,但是大受震撼。
原来在 3号位,创建协程的时候,指定栈地址的时候,使用的就是 S->stack。 也就是,所有的协程,都是使用的同一条栈。
自然挂起协程的时候,要把栈“复制到别的地方”。而恢复协程的时候,就要把在别的地方保存的栈复制回来。
这种操作只能说,惊为天人。叹为观止。
所以,那些叫嚣着,“那我不要调度器,创建后强行 resume 也能脱离调度器使用吧” 这样的行为就一定会崩溃。
因为这个 resume 操作,注定只能在 主线程栈里进行。也就是说,协程不能通过调用 resume 直接切换到另一个协程。因为他们俩使用的是同一个栈。只能通过yield 回到主线程,在主线程的栈环境上,才能操作 memcpy 复制协程的栈。
现在知道为何他要在恢复的时候才调用 make_context 创建协程了吧。 因为他使用的是同一个栈,如果在协程里面创建新协程(很自然很正常的需求),则一定会发生数据覆写问题。
为啥云风会如此设计呢?
因为一个很简单的道理:云风不知道在 ucontext 里如何正确的实现栈回收操作。 他在自己的blog里说,是因为协程大部分情况下使用的栈都很少,每个协程都分配一个栈会消耗太多内存。 其实他这是在忽悠人呢。因为很多人会被他这句话糊到。 需要对操作系统了解比较深的人才会知道,协程栈需要的内存可以让操作系统“按需分配”。用不到的栈内存,只是“挤占了那段地址范围”,实际并不占用内存。
而真正的原因,就是他不知道 ucontext规则下,如何实现栈内存回收。
我们来看以下,在 universal_fiber.h 的代码里,我是如何实现 ucontext 的栈内存回收的。
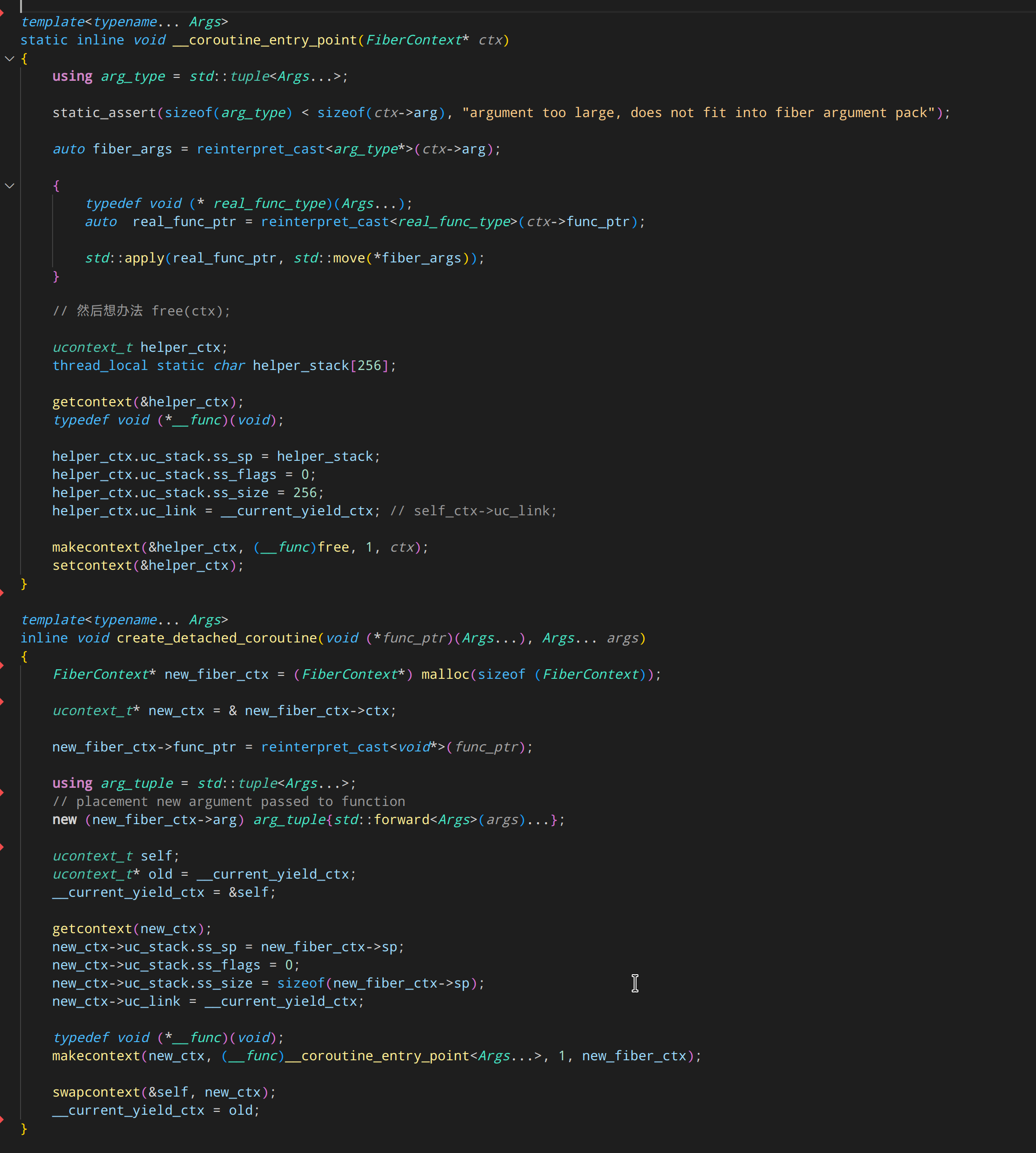
在 create_detached_coroutine 里,通过
FiberContext* new_fiber_ctx = (FiberContext*) malloc(sizeof (FiberContext));
分配了一个协程环境。这个 FiberContext 是一个体积 1MB 的巨大结构体。 实际上这里可以调用 mmap 分配 “按需增长” 的内存。但是为了简单起见这里直接使用 malloc.
接着调用 makecontext 准备好协程上下文环境。
注意这里,使用的协程入口函数是 __coroutine_entry_point<Args...>
这也是 C 语言所不能实现的功能。 __coroutine_entry_point 这个模板会根据 协程具体的参数自动实例化。 从而避免依赖 make_context 本身的 “多参数机制”。因为这个多参数机制是无法传递 C++ 对象的。
在 __coroutine_entry_point 里,将参数解包后, 就可以利用 std::apply 将 tuple 打包的参数作为 func_ptr 的参数进行调用了。
接下来,就是如注释说的,接下来要想办法释放 FiberContext* ctx。
直接调用 free 会必然崩溃。因为 ctx 同时提供了 当前栈。
所以就通过 makecontext 重新创建一个新协程,并且使用一个 static 的数组变量(因为是 static 变量,因此无需分配,无需释放)作为新协程的栈。
然后 setcontext 过去,新协程就自然跑起来。而新协程实际上的入口点,就是 C 函数 free()。
于是新协程运行起来,就把 ctx 释放了。 由于配置了 uc_link = 。因此 free 完成后,由 makecontext 创建的内部代码自动实现 setcontext 到 uc_link 指向的协程。
于是完成了协程退出的时候自动释放栈并切换到别的协程上。
这样需要思考得来的代码,云风显然是无法编写出来的。
因为他的协程,退出自动删除是这么写的
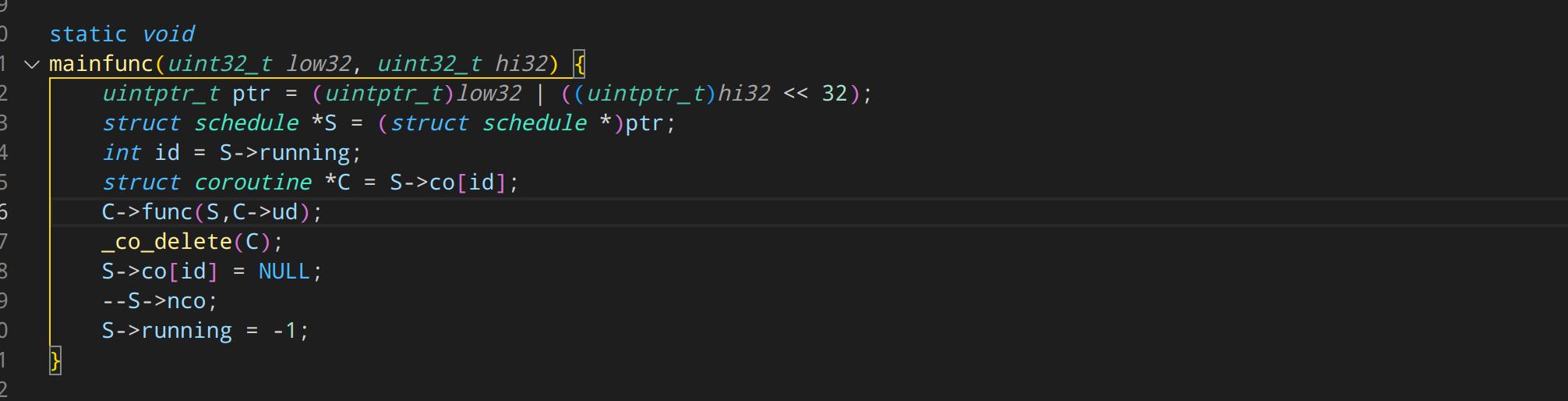
在包裹的协程入口代码里,调用那个 C->func(S, C->ud) 算是调用了用户的协程函数。 然后用户的协程函数返回的时候,调用 _co_delete(C) 将自己删除。
注意此时这个代码,运行在 S->stack 这个栈上!因此可以直接将 C 释放。明白了吧?
云风其实是因为思考了很久不知道怎么在当前栈还在 C->stack 上的时候释放 C。 于是整出了大家都用 S->stack 运行,那 C 就可以随时释放了。
所以说,技术网红都是水货一个
隔壁老王曾经 说过,
Comments所以要判断一个人是哪方面的大佬,就看他活跃在哪里,哪里写的东西多,这样判断就好了,如果活跃在github或各种邮件列表的各种项目,自然就是程序大佬,如果主要活跃在社交平台,自然就不是程序大佬而是网红了。