有栈协程的核心是执行上下文。执行上下文的核心是栈。
因此,切换栈就等于切换了上下文。
栈在协程切换上的核心地位
栈,存储了一个协程/线程 的“调用链”,以及依附于这条链上的“变量”。
没有栈,ret 指令将无所适从。
虽说栈是核心,但是栈本质是堆叠存储“历史 寄存器状态”。而当前没有入栈的寄存器状态,才是真正的当前上下文。
因此,很多古代协程库的做法,是栈协程“句柄” 上,开辟一个数百字节的空间。用于存放当下的CPU寄存器的数值。 上下文切换的时候,就是把当前 cpu 寄存器拷到句柄空间,然后从新协程的句柄空间里把寄存器的值一个一个读回来。
这种做法,是认可 “CPU寄存器数值的集合” 是当前上下文。栈不过是其中一个寄存器指向的一块内存区域,没什么特别的。
但是,boost.fcontext 另辟蹊径。他唯一指定 栈为协程的正统核心。当前的 cpu 寄存器状态,可以通过“调用 上下文切换” 函数,变成 上一层的 “历史状态”。
于是本层所要做的,就只是切换栈。在切换栈前,也只须将本层寄存器状态入栈。切换后,再将寄存器状态出栈。
因此,在 boost.fcontext 眼里,代表协程正统的,不是那个存储了几百个字节的寄存器数值的句柄空间,而是 栈顶指针。
而用于引用协程的那个句柄, fcontext_t 结构,不过就是存储了一个栈顶指针。 而不像 ucontext_t 那样,好家伙洋洋洒洒数百字节体积。
这就是对“何谓上下文”的理解理念不同带来的设计差异。
这点设计差异,造成了数据结构的不同。数据结构都不同了,自然上下文切换的代码也不尽相同了。正是所谓的,数据结构决定了算法。
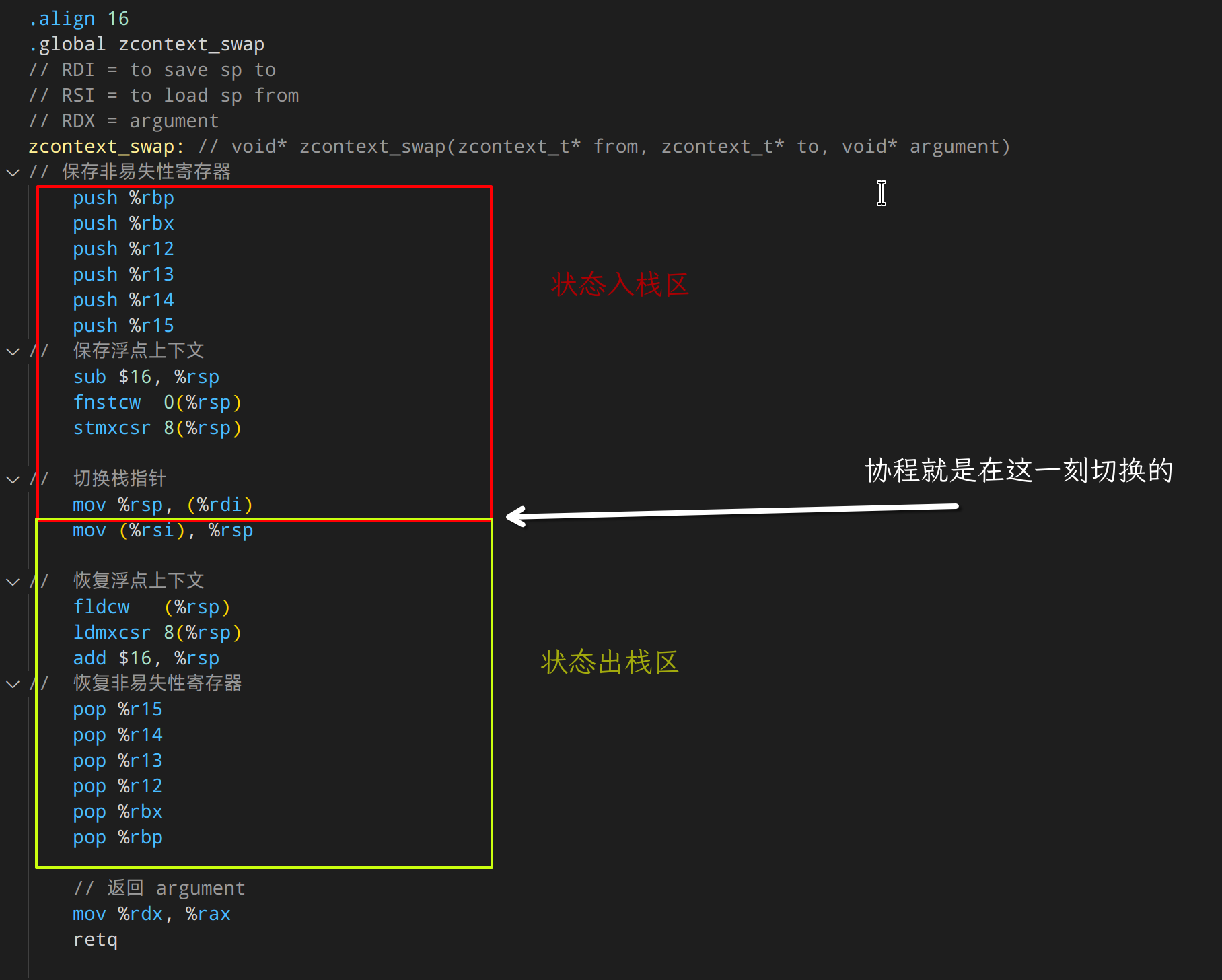
来个上下文切换代码看看
作为对比,看下 ucontext 系是怎么做上下文切换的:
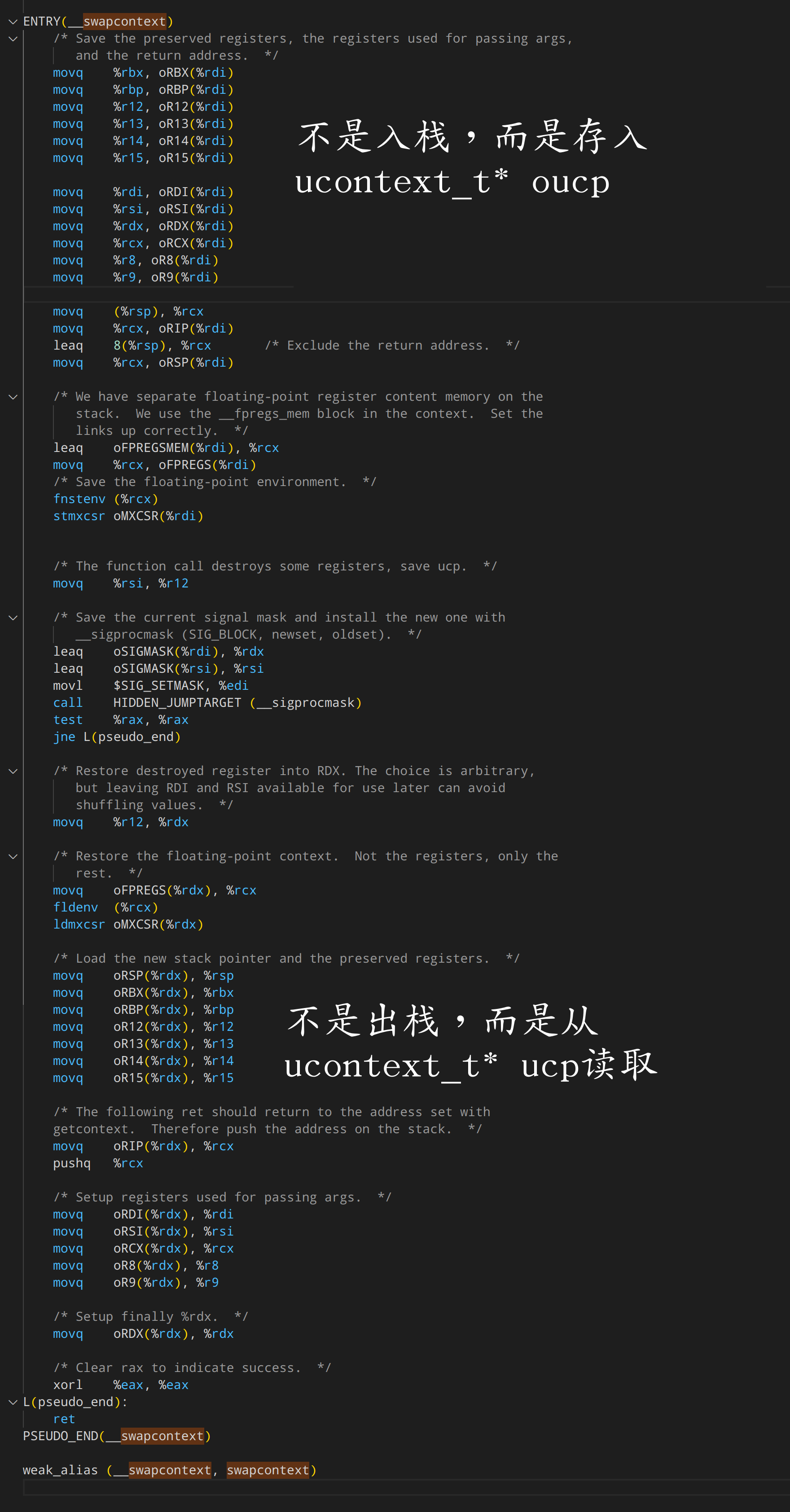
这就是不同的设计理念带来的差异。
ucontext 认为 cpu寄存器是上下文,栈只是其中一个寄存器所引用的附属上下文。 而 boost.fcontext 则认为,栈就是上下文的全部。包括了所有的寄存器历史。
所谓寄存器的历史,是说进行函数调用的时候,编译器会生成入栈指令保留寄存器的数值,以便函数返回后能恢复这些寄存器的值。于是在调用链上,每一层调用帧上面都保留了一份寄存器的“快照‘
既然寄存器的快照就在栈上留着,那只要把当前的状态再“压栈”一次。那么所有的上下文,不就都用一个栈顶表达了吗?
显然我们会发现,将栈视为协程的核心,能极大的简化代码。
这点差异,还影响了 make_context 的设计。
新建协程
一个协程上下文切换库,只需要编写3个函数
- 上下文切换
- 新上下文创建
- 新上下文的出生点
其中,新建上下文的出生点代码,是不需要暴露给用户的内部使用代码。另外两个,是作为库接口的形式存在的。
上下文的切换,在上节已经赘述过了。就是当前状态 push 入栈。然后切换栈顶,然后 pop 出栈。大功告成。
傻瓜式的代码。
接下来讲解下,如何创建新上下文。
通常来说,创建新协程,需要3个参数:
- 新协程的栈
- 新协程的用户代码入口(传一个函数指针)
- 新协程函数的参数 用万恶的void*吧 :)
有“创建后即刻运行”,和创建后不运行,调用 上下文切换 切过去后方可运行 两种工作模式。
一般我们选择 创建后不运行,需要主动调用 上下文切换 才开始运行。
那么我们仔细思考前面的上下文切换的代码。 这个代码在切换了栈之后,恢复了一系列寄存器后,执行了 ret 指令。
这个 ret指令就是返回到了新的栈上的调用方。
对于一个新创建的协程,我们可以 直接构造 它处于调用了上下文切换,等待返回这么一个状态。
也就是说,假设有这么一个启动函数:
__coroutine_entry:
;
; same as C code
; arg = swap_context(from, to, 0);
; user_function(arg);
call swap_context
; get user_function from stack
real_entry:
pop rbx
; pass arguments to user function
mov rdi, rax
; call user function
call rbx
我们创建新协程的时候,就是让这个协程,处于 call swap_context 已经调用,然后控制权切走,因此还没返回的状态。等这个新协程创建好了,然后调用 swap_context 它就立马从 swap_context 返回,然后接着 调用 用户函数完成启动。
实际上,在标签 real_entry 之前的代码,是不需要存在的。因为它从创建起来,就已经处于等待返回到real_entry的地步了。
对于这么一个状态,其栈是这样的:
note:栈从右向左增长,地址从左到右增加。每个格子表示 8 个字节。
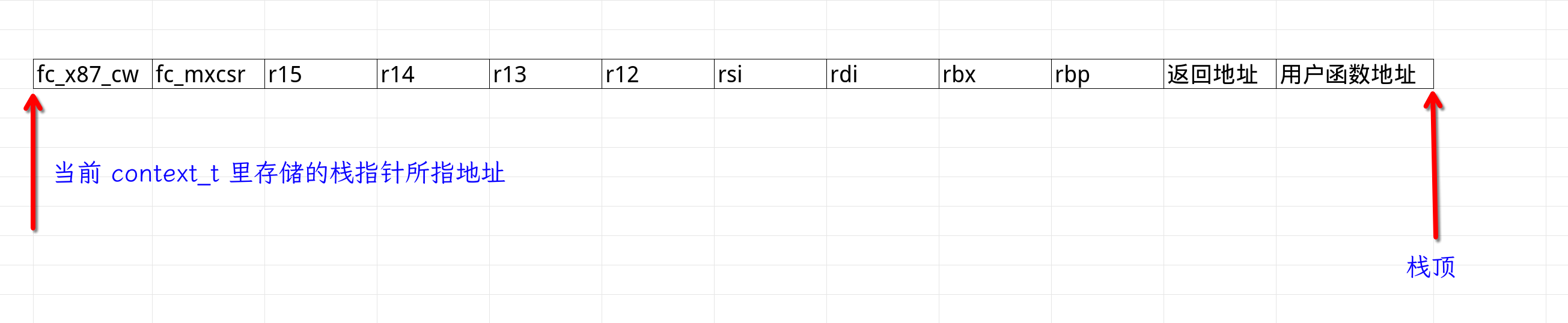
那么,只要构造好这么一个栈,返回地址填real_entry: 那行的地址。用户函数地址填 make_context 的时候传入的地址。
接下来 swap_context 的 ret 就会到 real_entry: 那行。然后一个 pop 就把传入的用户函数地址存入 rbx 寄存器。接着 mov rdi, rax 将 rax 存入 rdi寄存器。rdi 也是函数第一个参数。 然后 call rbx 就正式跳入 用户代码了。
协程就这样启动了。
实际上,对于初始协程来说,他初始寄存器的数值是啥根本没有关心的意义。
因此,make_context 实际上要坐的,就只是填好返回地址和用户函数地址。
也就是说,将传入的栈顶地址减少 96 字节存入 context_t 里。 然后按图中所示在指定的偏移出写入 real_entry 的地址,和用户传入的函数指针。
因此,编写一个上下文切换库所需的3个函数。 只有2个需要写汇编。一个可以用 C 语言完成。 需要写汇编的那两个,其中一个还特别段,三行代码的事情。
跨平台
其实,一个上下文切换库,最大的工作量在跨平台。因为别以为3个函数有一个是 C 写的就跨平台了。 其实并不。 三个都需要针对平台重写。
这个 “平台”,不单单是不同的 CPU 上要写一组,还有不同的“调用约定”下也要写一组。
因此要编写的数量是 CPU架构数*操作系统*调用约定*汇编器数目。
这也难怪 boost.fcontext 里有近百份汇编源码文件了。这膨胀的相当的厉害。
Comments