在基本完成 iocp4linux 后,我抽空在 rockpi 上测了下性能。
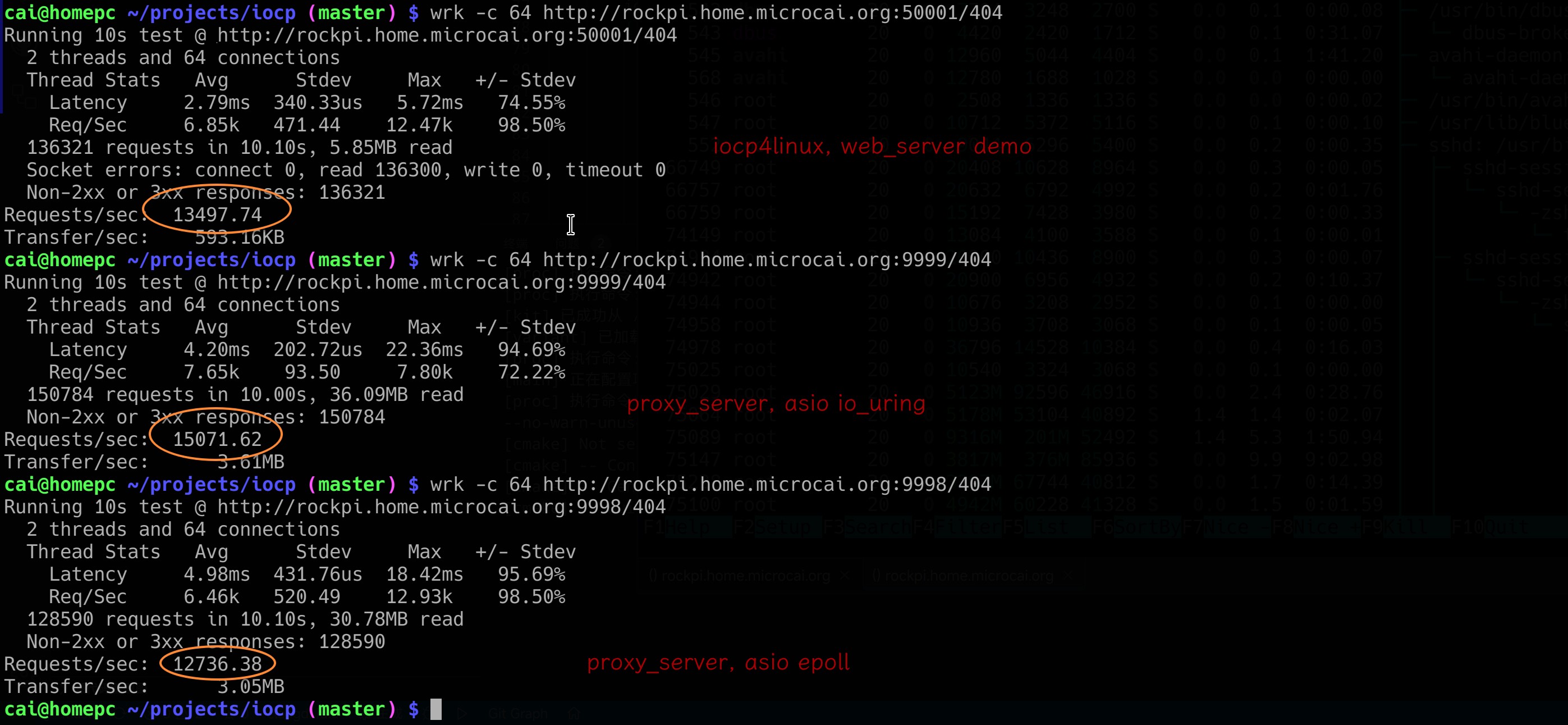
使用仓库里自带的例子 test/web_server/server.cpp,我测得了大约 6000req/s 的性能。
还不错。但是和 PC 上超过十万的性能相比,有那么点。。。弱鸡。
但是我通过 htop 注意到了一点。wrk 压测的时候, cpu1 是 cpu 100%。而且都是 红色的。说明cpu 都花在内核时间上了。 这也是 io_uring 很牛逼的原因:活都让内核干了。
==。
rockpi 是个6核的soc, 其中 cpu1-cpu4 (我设定 htop 的 cpu 从 1 开始数。)是个 1.4Ghz 的小核。cpu5,cpu6 才是 1.8Ghz 的大核。
这 不仅仅一核有难,5核围观。这特么干活的还是个小核。
于是果断找原因,发现是中断亲和性的设定问题。将中断迁移到 cpu5 后,测试发现干活的就是 1.8Ghz 的大核啦。
然后性能飙到超过 9000req/s。
之前测试的性能忘记记录了,这次随手截图留存了。
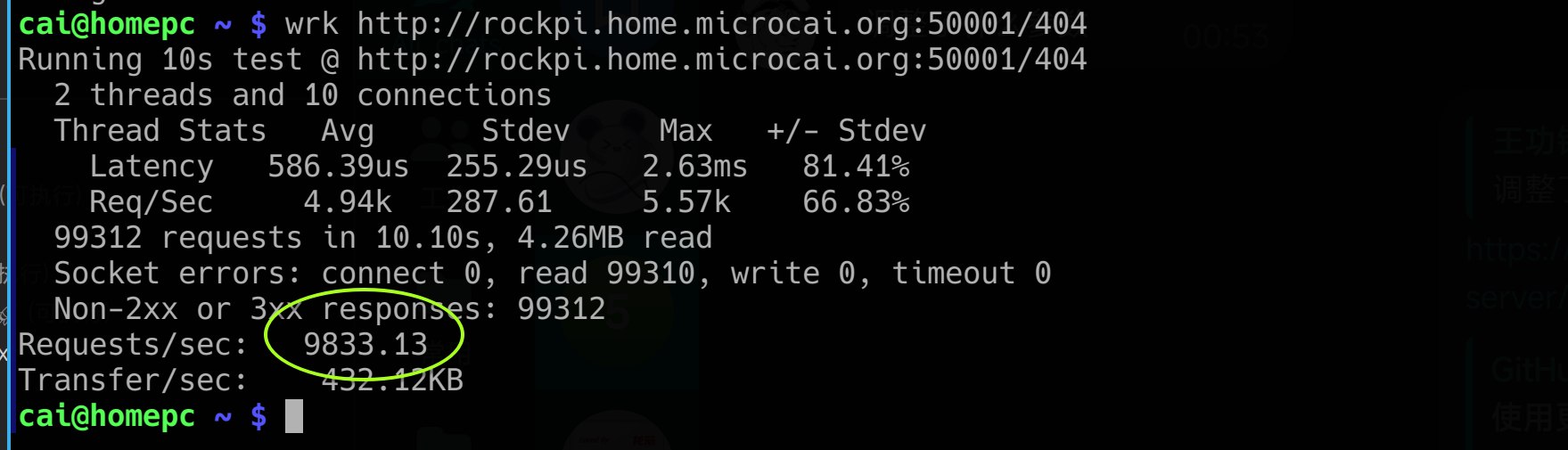
嘿嘿,果然给力。这优化。还是免费的。
就在我沾沾自喜的时候,我又随手测试了以下 老中医写的 proxy_server。它里面带了一个简单的 http server。 wrk 压测以下,我了个去的。轻轻松松 1.6万req/s。
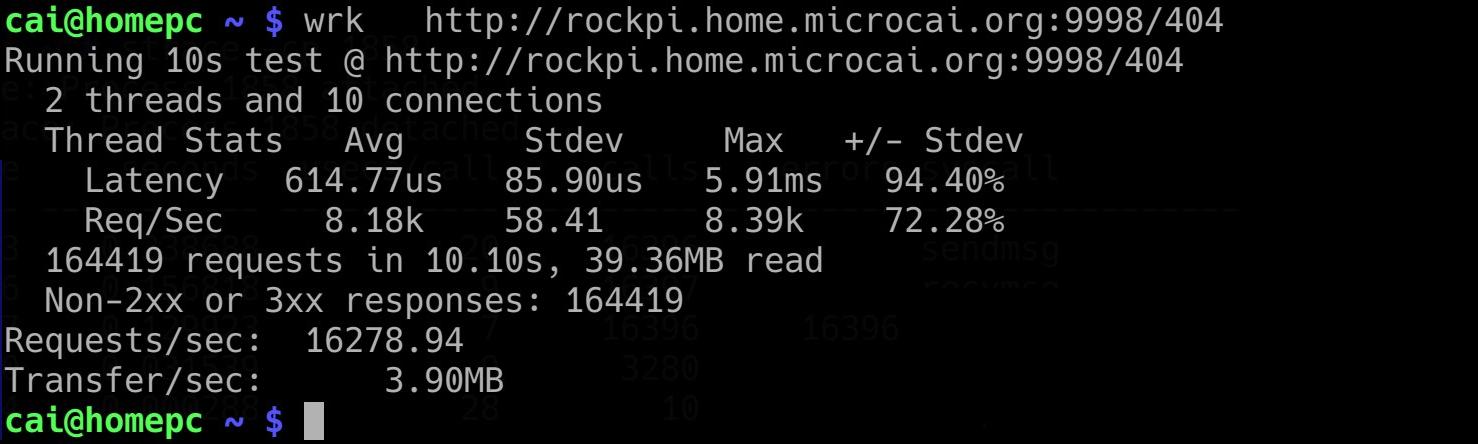
asio 你大爷还是你大爷!
于是我琢磨着进行优化。
我想到了 io_uring 提交 IO 的两步曲:
io_uring_get_sqe()
io_uring_prepXXX
io_uring_submit()
io_uring_get_sqe 获取到 一个 SEQ 表项后,调用 io_uring_prepXXX 将这个表项配置为相应的 IO 操作。 最后使用 io_uring_submit 提交。
这里,io_uring_submit 是可以批量提交的。可以多次使用 io_uring_get_sqe,准备好多表项。 然后一次性提交。
本来这个一次性提交的模式,我是不打算用的。
主要原因是我并不觉得一次性提交多个 IO 有什么“节约”的。而且会带来“延迟”。因为需要收集多个 IO操作后才批量提交。
但是,我祭出 strace 后,测得在 rockpi 上,一次 io_uring_enter 调用的开销高达 45us!
当然,打开 strace 调试后,性能会掉到只有一千多 req/s。这样算来一次 io_uring_enter 调用的开销也是 4us 量级的。
于是,先修改一个地方
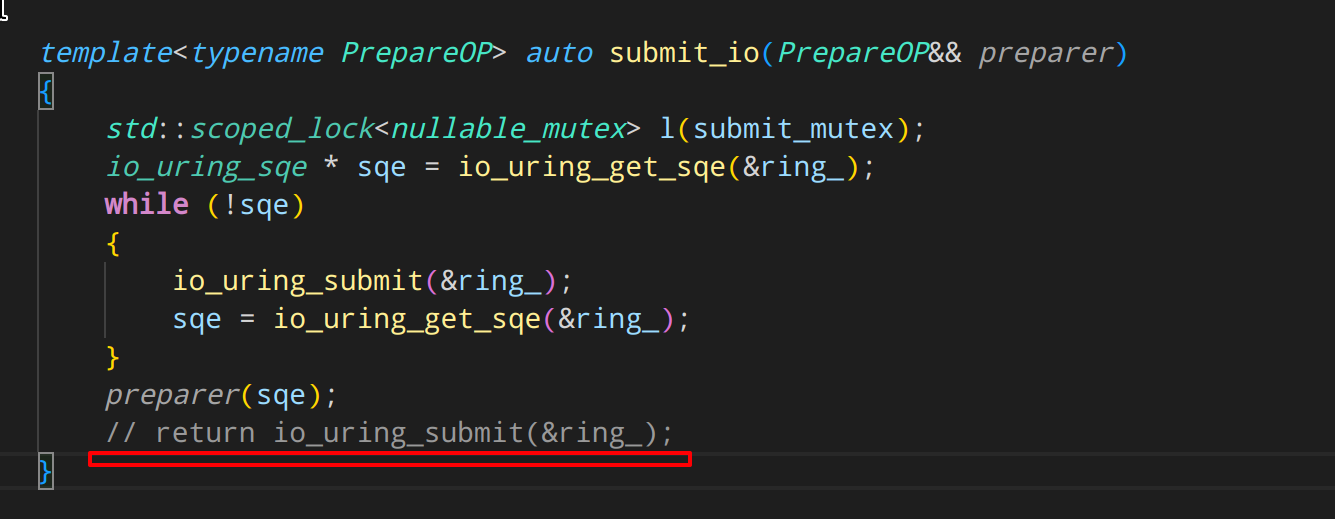
将立即 submit 的地方给注释了。
然后在 GetQueuedCompletionStatus 的实现里,先调用 submit 后等待IO结果。

结果发现性能毫无提升。。
原来是 GetQueuedCompletionStatus 的API设计限制。这个 API 本来就只能返回一个结果。
按我示例程序的逻辑,每次 GetQueuedCompletionStatus 返回,就要 resume 一个协程。 每次 resume 一个协程,协程内部也就只会调用一个重叠 IO。然后就调用 co_await 等待IO, 控制权就转回事件循环,然后调用 GetQueuedCompletionStatus 获取下一个事件。
所以我在 AcceptEx, WSASend, WSARecv 之类的实现里,每次准备好 SEQ ,然后不提交。 结果只是把提交延迟到调用 GetQueuedCompletionStatus 的时候。
调试结果也验证了我的看法。每次 GetQueuedCompletionStatus 里的 io_uring_submit 只提交了一个 IO操作 。。。。
看来 IOCP 的缺陷。就无法享受批量提交带来的性能优势了。
本来这事应该会告一段落。以上多提交的修改,甚至并不是如我所言,是在测试 rockpi 上的性能落后 asio 的时候才奋发图强的去改的。而是在最初的开发阶段就做了。结果发现不会带来性能提升。
因为 GetQueuedCompletionStatus 就是一次一个的。
但是受 asio 的性能刺激,我受不了了,于是仔细的研究了自己随手写的 GetQueuedCompletionStatus 事件循环的代码(也就是上文里介绍的 universal_async.hpp 里的 run_event_loop )。
突然想到了一点。就是 GetQueuedCompletionStatus 为啥要获取结果就立马执行协程完成事件呢?
如果先批量GetQueuedCompletionStatus获取结果,直到情况内核完成列队。然后批量执行完成事件。
那么在批量执行完成事件的时候,就一定会批量投递出新的 IO.
等批量的IO完成事件执行完了,循环又重新回到 GetQueuedCompletionStatus 获取IO结果,而此时 待提交的 IO 一定非常多!!!
此时 GetQueuedCompletionStatus 内的 io_uring_submit 就必然是一个大批量提交。
同时,由于会批量调用 GetQueuedCompletionStatus 获取,因此不能每次 GetQueuedCompletionStatus 都调用一次 io_uring_submit。 于是我把 timeout 参数 = 0 的 GetQueuedCompletionStatus 调用,修改为调用 io_uring_peek_cqe。这个 io_uring_peek_cqe 不会陷入内核。而是直接从 CQ这个无锁列队里拿数据。只有拿不到数据了,再考虑调用 submit 提交。 提交完了,再用个延时很低的 io_uring_wait_cqe_timeout 看 内核能不能马上在很短的时间内给出结果。如果不能,就返回 GetQueuedCompletionStatus 失败。让 run_event_loop 换 timeout = 无穷大 的参数重新进入 GetQueuedCompletionStatus 循环。当然,重新用无穷等待时间进入 GetQueuedCompletionStatus 前,会把已经 获取到的完成事件先执行了。
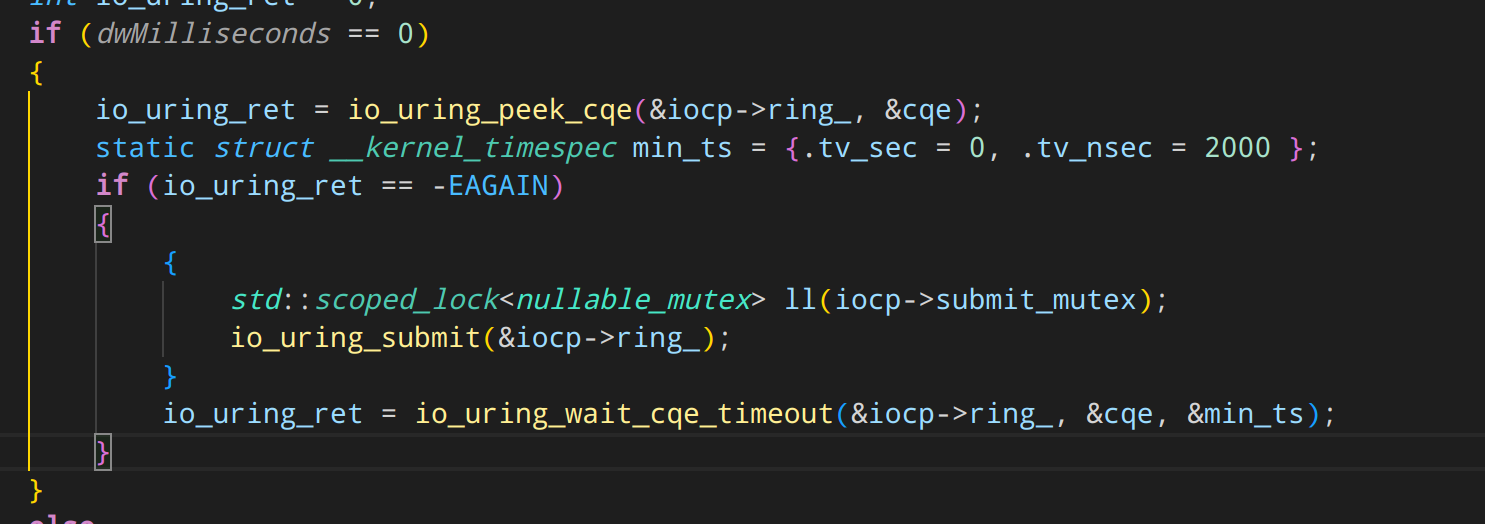
如此修改后,果然性能提高了!!
然后,通过 strace 检查
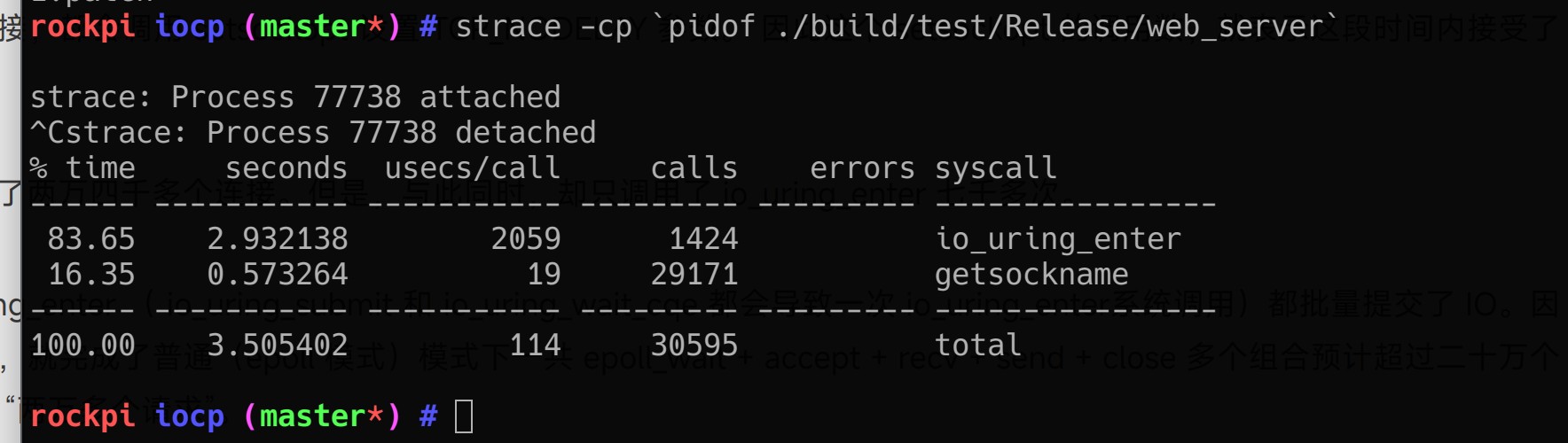
由于每次接受连接,都会调用 getsockname 获取对方 socket 地址。 因此这个 getsockname 的调用数,就表示这段时间内接受了的连接数。
而图中一共接受了两万九千多个连接。但是,与此同时,却只调用了 io_uring_enter 一千多次。
说明每次 io_uring_enter ( io_uring_submit 和 io_uring_wait_cqe 都会导致一次 io_uring_enter系统调用)都批量提交了 IO。因此系统调用数七千多,就完成了普通(epoll 模式)模式下一共 epoll_wait + accept + recv + send + close 多个组合预计超过三十万个 系统调用才能处理的 “两万多个请求”。
将处理两万多个 http 请求所需要的系统调用数量从二十多万缩减到一千多个。
于是获得了巨大的性能提升。
当然,最终一万三的处理数,还是败给一万六的 asio 。。。。不过有点欣慰的是超过了 epoll 模式的 asio 了。
ASIO 你大爷还是你大爷。
Comments