序
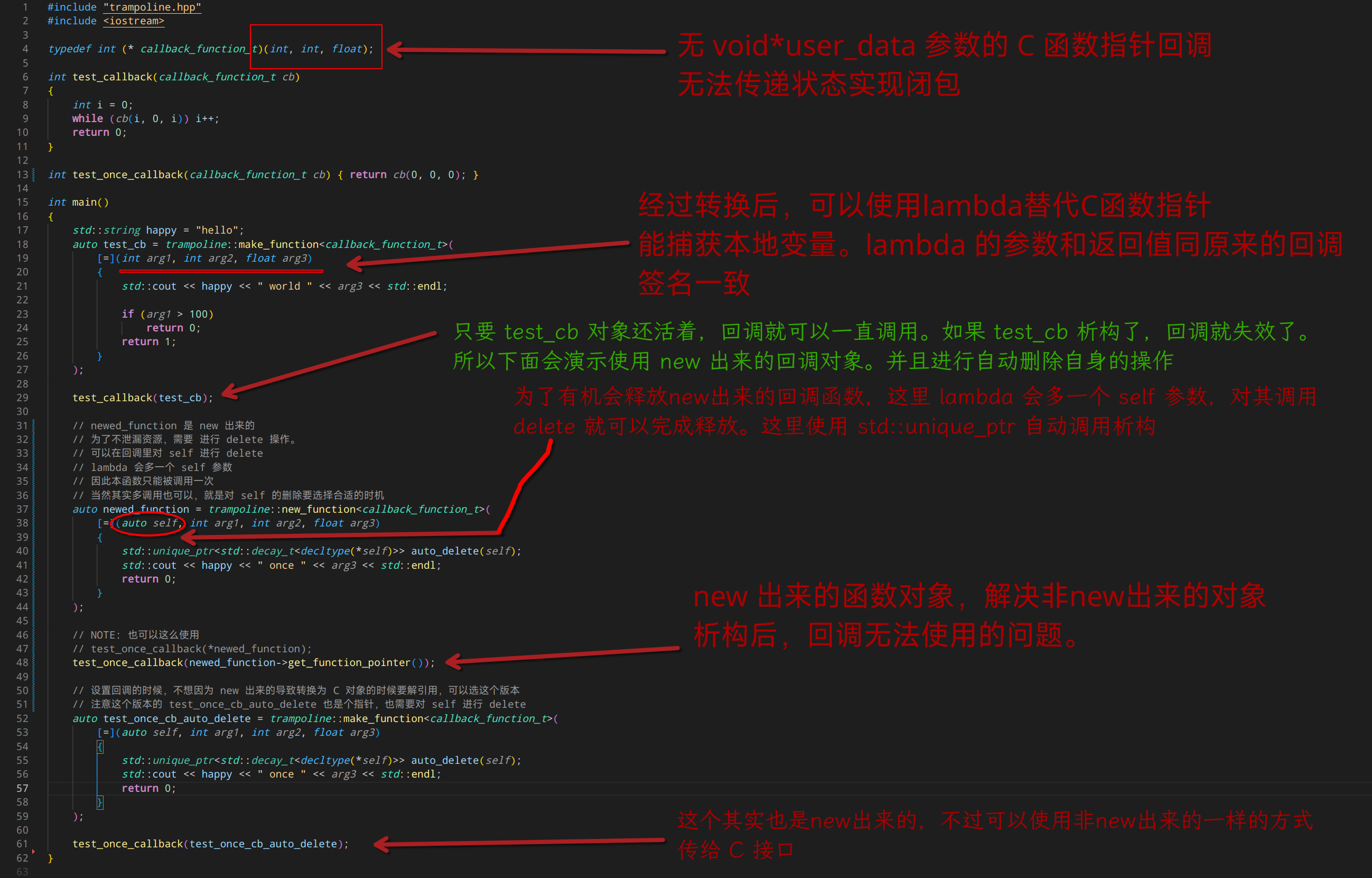
十年前,我曾经写过一个让 C 形式的回调函数支持 闭包的小转换工具, 见这。
那时候,我说过,要想把 boost.function 传给 C 接口,那这个 C 接口,必须得带一个 void* user_data 的参数。
比如
typedef int (*callback_t)(int arg1, int arg2, void* user_data);
bool register_callback(callback_t cb, void* user_data);
可以利用这个 cfuntion,把 boost::function<int(int, int)> 给当成 callback_t 使用。
而 boost::function 本身又可以接受 lambda, boost::bind , 从而组合出非常易用的使用方式。
但是,这十年来,我也偶尔会遇到一些 C 库的 api , 他就只能接受裸指针,不能接受 void* user_data
typedef int (*callback_t)(int arg1, int arg2);
bool register_callback(callback_t cb);
这就很难受了。因为没有办法传递 void*, 也就无法给回调函数设置“上下文”。也就彻底失去了上下文关联能力了。不得不将所需的 数据通过“全局变量”传递给回调函数。十分丑陋不说,还导致回调函数变成了无法重入的。
转机
其实,如果使用 GCC 编译器,GCC 也提供一个叫 “nested function” 的功能,比如
typedef int (*callback_t)(int arg1, int arg2);
bool register_callback(callback_t cb);
int main()
{
int hello = 1;
int nested_function(int arg1, int arg2)
{
printf("hello = %d\n", hello);
}
register_callback(nested_function);
}
这个 nested_function 能访问 main 里定义的对象,算的上一种“闭包”了,但是,它仍然可以转换为不需要 void* 的裸函数指针。
不过, gcc 并没有进一步发掘 nested function 的魅力。nested_function 在 main 退出后,就会失效。因为它是使用 栈 来存储闭包数据的。也就是说,register_callback其实必须在返回前就调用 nested_function。否则 nested_function 就失效了。
但是,即便 gcc 的 nested function 有缺陷,但是其背后的实现手法,也值得让我研究。因为它的函数指针,可以隐含一个 void*user_data。
其实 gcc 的实现方式,是把你写的 nested_function,改写为
int __nested_function(int arg1, int arg2, struct captured_data* trampoline_data)
{
printf("hello = %d\n", trampoline_data->hello);
}
接着,当运行到这个地方的时候,它在运行时 动态 的编出一个这样的 nested_function
int nested_function(int arg1, int arg2)
{
uint8_t * program_pointer = get_program_pointer();
struct captured_data* trampoline_data = (struct captured_data*)(&program_pointer[offset]);
__nested_function(arg1, arg2, trampoline_data);
}
具体的,你的代码是被这样转换的:
int main()
{
int hello = 1;
struct captured_data {
int& hello;
};
int __nested_function(int arg1, int arg2, struct captured_data* trampoline_data)
{
printf("hello = %d\n", trampoline_data->hello);
}
int nested_function_template(int arg1, int arg2)
{
uint8_t * program_pointer = get_program_pointer();
struct captured_data* trampoline_data = (struct captured_data*)(&program_pointer[trampoline_size]);
__nested_function(arg1, arg2, trampoline_data);
}
char nested_function_prog[trampoline_size];
captured_data hiden_arg = { hello };
memcpy(nested_function_prog, &nested_function_template, sizeof nested_function_template);
memcpy(nested_function_prog + trampoline_size, &hiden_arg, sizeof (&hiden_arg));
callback_t nested_function = (callback_t) nested_function_prog;
register_callback(nested_function);
}
这个 nested_function 是在当前 “栈” 上创建的。因此这个功能,还要求 “栈内存可执行”。
虽说是 “动态创建”,其实不过是预先编译了一个 “模板”,这个模板在相对 “指令指针” 的固定位置,存储一个指针。 因此,这个模板可以随时 memcpy 的方式复制到一个新的位置执行。只不过,复制后,要在那个偏移位置,”写入“ 创建的数据对象的地址。 这样这个 动态创建的函数,它就可以在运行时找到那个函数。所以,其实并不是在运行时才 编译 nested_function。而是先编译了一个 位置无关 版本的作为模板。 然后运行时再把模板搭数据,拷贝到 分配的栈内存里。然后把这份实例化的函数作为 nested_function 使用。
顺着 GCC 的思路。完全可以把 栈 创建给修改为 堆 创建,就完全实现了 lambda 转裸函数指针 的要求。
用 C++ 实现一个
C 语言是没有模板的,不过编译器内部实现,也不需要 C 语言有啥模板。
但是,我们要实现“任意 lambda” 转换为函数指针,那就得使用 C++ 的模板机制。而且,不同的函数,还得“共享” 同一份汇编写的 trampoline 代码模板。 编译器可以为 nest_function 立即生成一份它独有的 trampoline 代码,但是,库作者只能使用语言本身的机制,又不能调用编译器。 所以,为了共享 trampoline 代码,我的设计思路是,首先使用 仿函数来做一次中转。
中转的思路是 调用方 -> trampoline -> 包装的仿函数 -> 真正的用户 lambda。
GCC 实现的 nested function 是把 trampoline -> 包装的仿函数 这俩代码给合并成一个。毕竟不同的 lambda 其实是需要不同的 包装器去 调用的。
所以,我的做法是,把 真正的用户 lambda ,给用 std::function 存起来。然后用模板去实现 包装的仿函数。业绩是说,包装的仿函数长这样
template<typename ReturnType, typename... Args>
struct wrapped_function
{
ReturnType operator()(Args... args)
{
return user_lambda(std::forward<Args>(args)...);
}
std::function<ReturnType(Args...)> user_lambda;
};
这样,就不需要为不同签名的函数,写无数种排列组合的 trampoline。 wrapped_function 根据用户的 lambda 动态创建出来。然后 trampoline 只需要找到 wrapped_function 的 this 指针。就可以调用了。那么 trampoline 也可以用模板实现出来
template<typename ReturnType, typename... Args>
ReturnType trampoline_function(Args... args)
{
// get this from IP
wrapped_function<ReturnType, Args...> * _func = get_this();
return (*_func)(std::forward<Args>(args)...);
};
trampoline_function 的签名,和 C 函数的回调是一模一样的,因此 trampoline_function 可以被 C 直接调用。。。
吗?
其实不能的。因为 trampoline_function 编译后,地址是固定的。根据之前 gcc 的实现分析, trampoline 的关键实现,就是有一份 “代码” 被动态的分配到内存里。 这个代码和数据放一起。偏移量是“编译期已知”的。于是,这个动态的代码,他可以利用 CPU 的 IP 寄存器,获取到和代码绑定的数据的地址。
因此,要再次改进思路,变成这样
中转的思路是 调用方 -> 汇编写的一段动态代码 –jmp–> trampoline_function -> 包装的仿函数 -> 真正的用户 lambda。
为啥要用汇编写一个呢?因为 trampoline_function 是个模板,它的大小是不固定的,不可能在运行时去 “复制”到 堆里。C++ 语言也没有一个机制获取一个代码编译后的二进制大小。
而这份手写的汇编代码,它就是 确定 的。因此这份手写的汇编代码,就可以被到处 复制,并且偏移量已知,可以在运行时 拼 上一份数据,从而将这个代码彻底变成可执行的代码。
并且,这个汇编代码,它一定是使用 JMP 指令去调用 trampoline_function, 而不是 call 指令。这样,这个 汇编代码,是不需要考虑“参数传递”这个问题的。 调用方传的参数, 交给模板编写的 trampoline_function 去“解码”。
那么汇编代码是怎么样的呢? 它长这样:
trampoline_function_entry:
lea rax, [rip] ; 将 rip 指针赋值给 rax
mov r10,[rax + 24] ; 固定 24 字节处偏移拿到 this
mov rax,[rax + 16] ; 固定 16 字节处拿到 trampoline_function 的地址
jmp rax ; // 跳转到 trampoline_function
trampoline_function 里,再使用“内联汇编”。 直接获取 r10 寄存器,就拿到了 包装的仿函数 的 this。
也就是
template<typename ReturnType, typename... Args>
ReturnType trampoline_function(Args... args)
{
// get this from IP
wrapped_function<ReturnType, Args...> * _func;
//内联汇编 从 r10 寄存器获得 _func
asm("mov %%r10, %0" :"=r"(_func));
return (*_func)(std::forward<Args>(args)...);
};
那么,当用户需要闭包转 裸函数的时候,就是 使用 mmap/VirtualAlloc 之类的内核提供的内存分配接口,分配一段“可执行”的内存。
然后把 trampoline_function_entry 复制过去,并且在固定的 16 字节和 24 字节处,填
入 wrapped_function<ReturnType, Args...> * 的地址和 trampoline_function 的地址。
放出完整源码
这就是核心机制了。实使用的时候,还得考虑 RAII, 还得考虑“方便用户使用”。因此做了些许调整。
比如 让 wrapped_function<ReturnType, Args...> 和 汇编写的 代码,被统一分配到一个内存页上。让这个新分配的代码,反而作为
wrapped_function 的首个成员,于是,this 就变成了 rip , 构建的时候,只要填入 trampoline_function 的地址,不必再
填入 wrapped_function 的地址。
另外函数名和类名,也有所调整。
anyway, 放出 github 仓库地址